
Mobile App Incrementality in Practice

As part of our ongoing research into how app marketers adapt to an evolving landscape of technology, data, and strategy, Bidease surveyed 100 UA marketers to uncover what’s really changing behind the scenes. Each post in this series highlights one insight shaping the future of programmatic growth, straight from the marketers driving it.
Mobile growth teams rely on attribution to understand performance: what happened, and which channels or campaigns drove it. But as signal loss increases and platform reporting becomes more opaque, attribution alone does not fully answer the question teams care about most: whether their spend is actually driving net new growth.
That is where incrementality testing comes in. It builds on attribution by helping teams understand causality, whether a campaign changed user behavior or simply captured demand that would have existed anyway. This is not a niche challenge limited to a single category. Across gaming, finance, streaming, and other app types, teams are all working toward the same goal, improving clarity in a more constrained measurement environment. To learn more, we surveyed 100 mobile growth marketers to benchmark how they are using incrementality testing today, why they run it, where it fits into their workflow, and how approaches vary across app categories.
Key Takeaway:
- Attribution shows what happened. Incrementality helps determine whether it actually mattered. It adds a layer of causal understanding that helps teams make more confident budget decisions.
Where Incrementality Happens: Ownership and Execution Models
Incrementality testing does not live in a single place. Most teams run tests across a mix of internal tools, platforms, and partners, depending on their resources and goals.
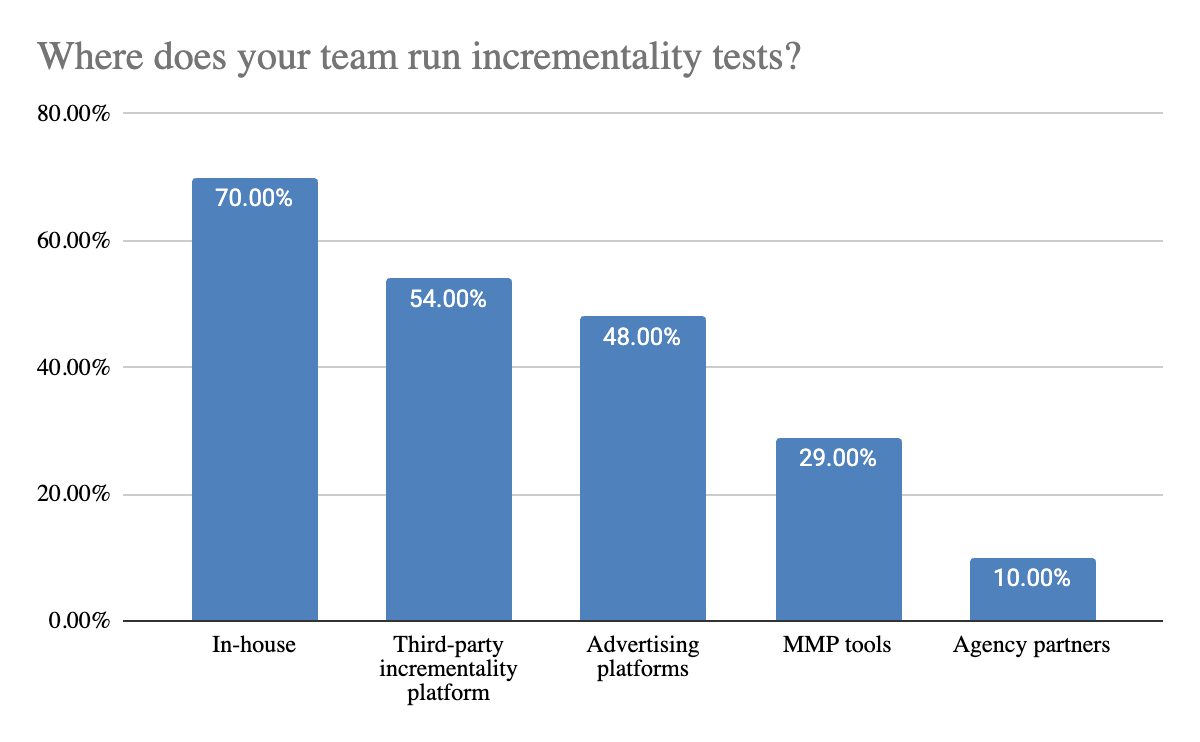
Ownership is clearly shifting in-house. 70% of teams report running incrementality tests internally, making it the most common approach, followed by 54% using third party incrementality platforms and 48% using advertising platforms, such as DSP tools. This suggests that while internal ownership is becoming the norm, most teams still rely on a combination of external tools to execute tests.
This creates fragmentation. Teams are not relying on a single testing environment, they are stitching together results from multiple sources. A marketer might run in house experiments, platform lift studies, and third party tests at the same time, each with different methodologies and assumptions. Even MMP based testing, used by 29% of teams, adds another layer to this mix.
But fragmentation does not come from teams alone. It is also built into how platforms execute incrementality testing. Each platform uses its own methodology, definitions of lift, and reporting frameworks, which makes it difficult to compare results directly across channels. The result is a measurement landscape that is difficult to standardize, where differences in methodology can matter just as much as differences in performance.
There is also a tradeoff between control and convenience. In-house testing gives teams more flexibility and visibility into how tests are designed and interpreted, while external tools reduce operational overhead and make it easier to run experiments at scale. In practice, most teams are balancing both. Where incrementality happens is not just an operational choice, it directly impacts how frequently tests are run and how confidently results can be used to guide decisions.
How Teams Test: Methods, Tradeoffs, and Maturity
Not all incrementality tests are created equal. Teams are using a wide range of methods, from quick directional checks to more rigorous experimental designs, depending on their resources, timelines, and tolerance for complexity.
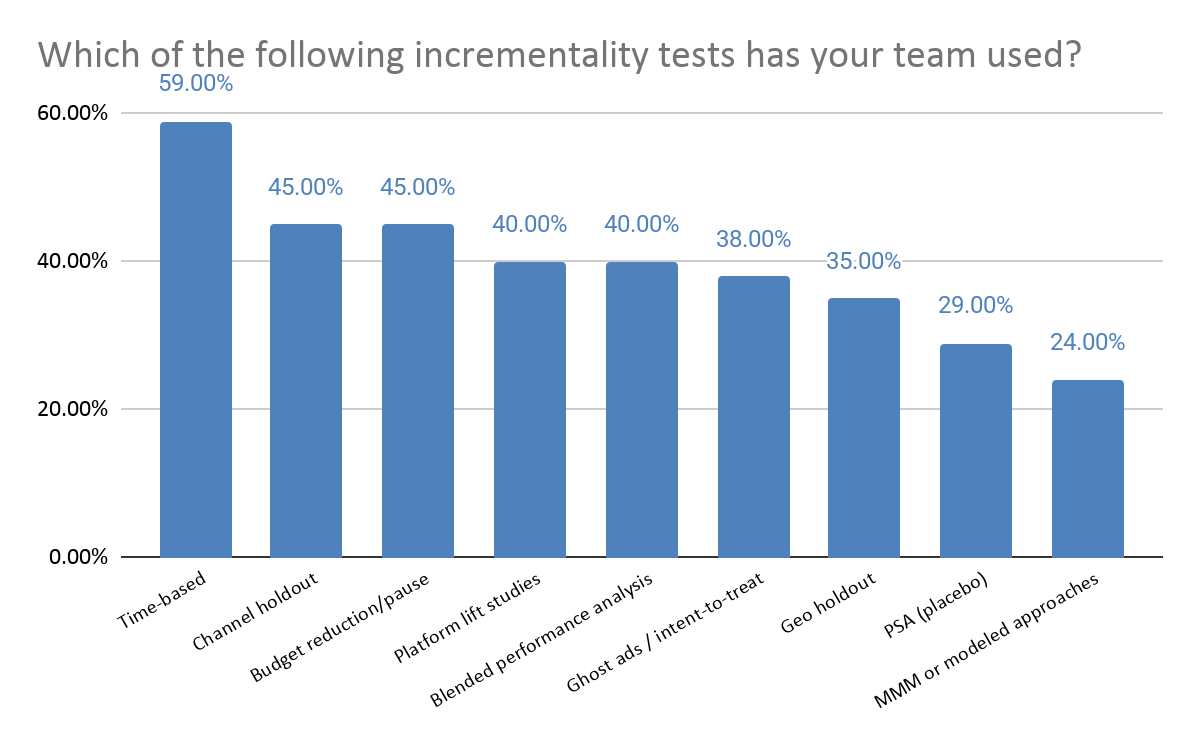
The data shows a clear spread across methods, with a strong skew toward easier to execute approaches. Time based tests are the most common (59%), followed by channel holdouts (45%) and budget reduction/pause tests (45%). More advanced methods like PSA testing and ghost ads are used far less frequently, reflecting the higher level of effort and expertise required to run them effectively.
This spread reflects the tradeoffs teams are making. Time-based tests, channel holdouts, and budget pause tests are relatively accessible and cost nothing to run, which likely helps explain their broader use. More rigorous approaches, such as geo holdouts, PSA tests, and ghost ads, can provide stronger causal evidence, but they also require more planning, cleaner market structure, and tighter experimental design.
There is also a clear divide between platform-led and independent testing. Platform lift studies, such as Meta Conversion Lift or similar studies run within ad platforms remain common (40%) because they are built into existing workflows and are relatively easy to deploy. Independent methods, whether run in house or through third party tools, offer more control and broader cross channel applicability, but often come with greater operational complexity. The result is a fragmented testing landscape where teams are usually choosing methods based on feasibility, not a shared standard for rigor.
Designing for Decision: Why Clear Goals Are Not Enough
Not a single team we surveyed runs incrementality tests without a goal. They typically have a clear decision in mind, whether that is increasing spend, validating a new channel, or improving efficiency. The role of incrementality testing is to provide the confidence needed to act on that decision.
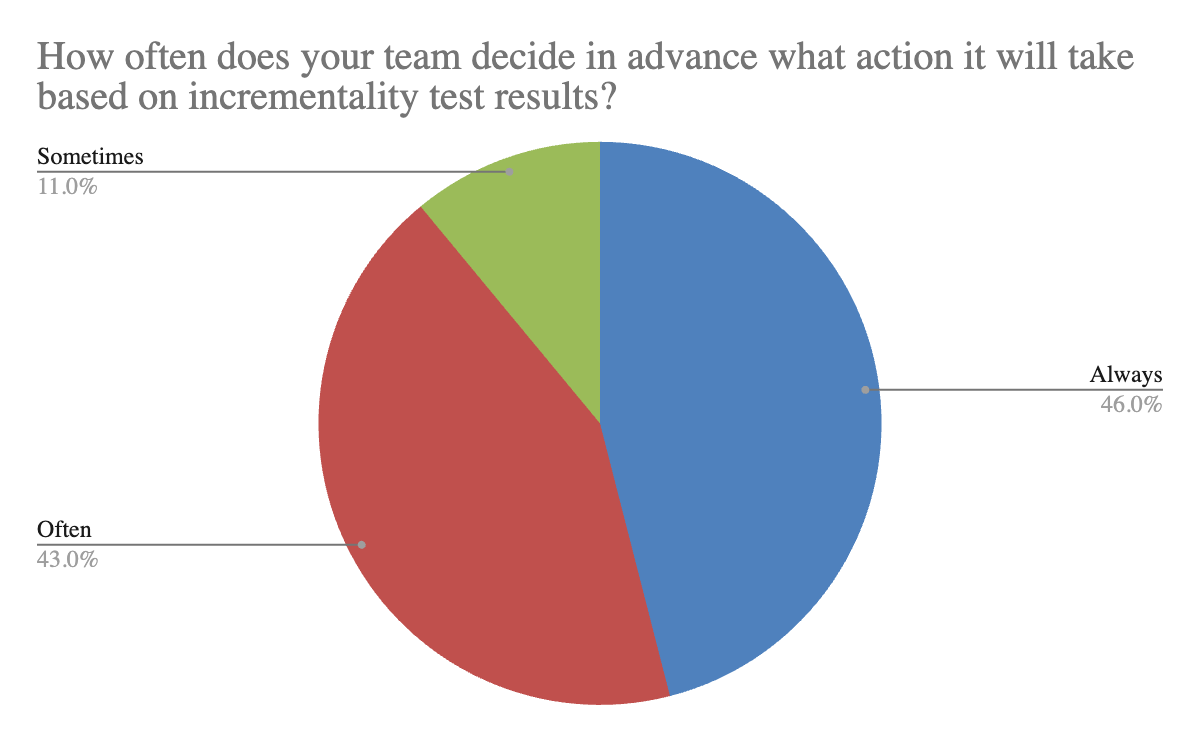
The data shows that 89% of teams are already thinking about outcomes before a test begins. This suggests that incrementality testing is increasingly tied to decision making, not treated as a purely exploratory exercise.
Where teams still fall short is in the level of rigor applied before launch. Defining the action is only one part of the equation. Without also estimating the required sample size, test duration, and minimum detectable effect, tests can still produce inconclusive or difficult-to-interpret results. In these cases, even well-intentioned tests may not provide the clarity needed to confidently move budget.
The difference between running tests and operationalizing incrementality comes down to consistency. High performing teams take a more data driven approach to incrementality, where experiments are designed with both statistical rigor and decision clarity in mind, even when tests involve tradeoffs like additional budget or temporary holdouts. Less mature approaches tend to run tests without a clear hypothesis or defined objective, often just to see what results emerge. Without a specific question or decision in mind, it becomes much harder to generate meaningful insights or apply learnings consistently across campaigns.
Incrementality by Vertical: Different Apps, Different Playbooks
Incrementality testing is not one size fits all. The way teams design and interpret tests is heavily shaped by the type of app they are growing, including differences in volume, conversion cycles, and revenue models.
The data shows that whether you're scaling a fintech app, a shopping platform, or a productivity tool, the struggle to prove incremental impact is universal. Our survey results were remarkably balanced across categories, led by Shopping (21%), Utility (19%), and Finance (18%). This diversity reflects a wide range of operating environments, each with its own constraints and testing requirements.
These differences directly impact how incrementality testing is approached. High volume categories like gaming are typically able to run more frequent tests and iterate quickly, since they can reach statistical significance faster. In contrast, categories like finance often operate with higher acquisition costs and lower conversion volume, which makes testing more resource intensive and places a greater emphasis on precision and experimental design.
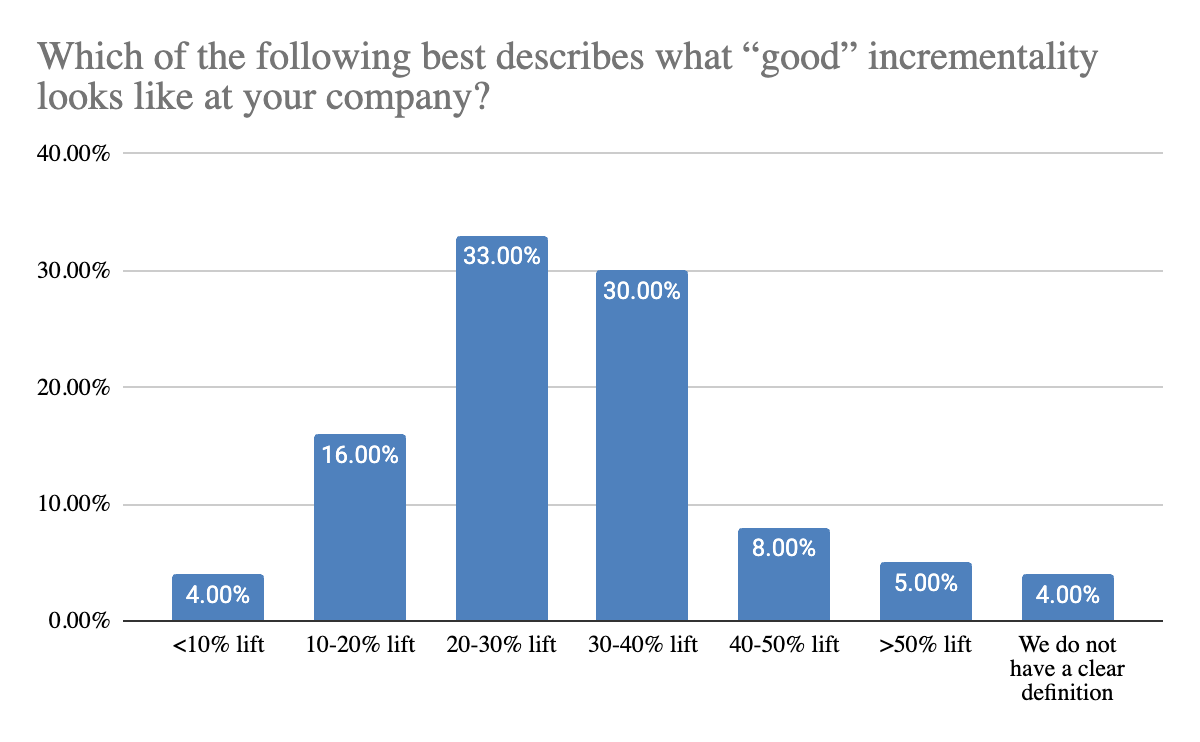
What “good” incremental lift looks like also varies meaningfully by category, and that difference is driven by underlying business economics. Gaming teams tend to expect higher lift, most commonly in the 30% to 40% range, which reflects their ability to scale quickly and absorb volatility. In contrast, utility and productivity apps are more likely to view 10% to 20% lift as meaningful, suggesting a greater focus on efficiency and consistent returns. Finance, streaming, and social apps fall in between, with expectations split between 20% to 40%, highlighting a balance between growth and cost control. The takeaway is that incrementality results are not absolute. A “good” result is defined by the constraints and economics of the business, not a universal benchmark.
What Teams Actually Learn: The Reality Check
Incrementality testing is often positioned as a way to challenge assumptions. In practice, most results are less dramatic. Teams are not consistently uncovering major overstatements or completely invalidating their existing strategies.
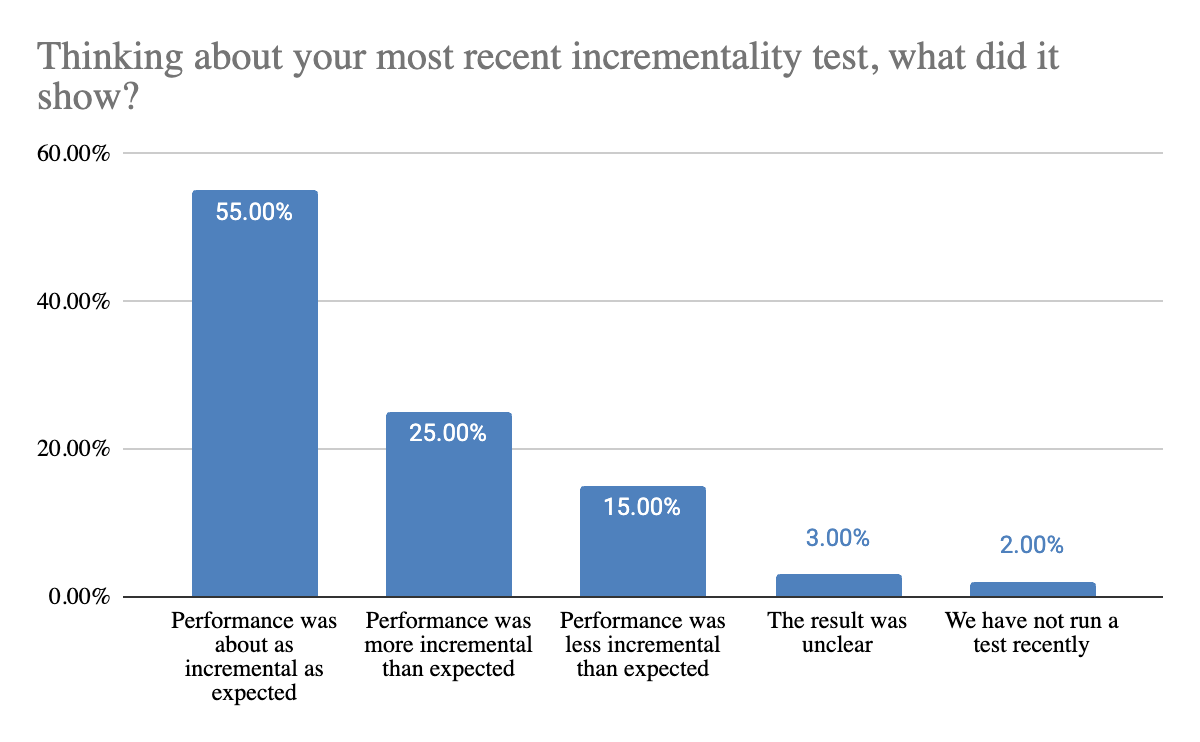
The data shows that while most tests confirm expectations, a significant share still reveal meaningful differences. 55% of teams report that performance was about as incremental as expected, while 25% saw stronger than expected results and 15% saw weaker performance. Only 3% reported unclear results. This means that 40% of teams are uncovering outcomes that differ from what they anticipated.
This balance is important. Incrementality is often used to validate and refine decisions, but it also plays a critical role in surfacing gaps between reported performance and actual impact. Even when results are directionally correct, these differences can influence how confidently teams allocate budget or prioritize channels.
That validation is critical because incrementality testing allows teams to build on reported performance and understand whether their largest investments are actually driving net new growth. In many cases, it helps confirm that core channels and partners are delivering the expected impact. In others, it highlights opportunities to reallocate spend toward areas with stronger incremental contribution. The objective is to identify partners whose reported metrics may be conservative but whose actual incremental impact is significant. By stress-testing these core investments, teams can either definitively validate their largest spends or unlock misallocated budgets that are ready to be deployed more effectively.
Gaming
Gaming teams tend to set a higher bar for performance, with most defining “good” incrementality as 30% to 40% lift. This reflects their ability to scale quickly and absorb volatility, given high conversion volume and fast feedback loops.
In terms of methodology, gaming teams most often rely on budget reduction or pause tests, with geo holdouts and channel holdouts also widely used. These approaches allow for faster iteration and clearer directional signals in high-volume environments.
This combination highlights a key advantage of gaming. With more data and faster cycles, teams can test more aggressively and prioritize speed alongside rigor, making incrementality a more flexible and iterative tool.
Finance / FinTech
Finance teams are split in how they define success, with responses evenly divided between 20% to 30% and 30% to 40% lift. These apps balance between growth expectations and the realities of higher acquisition costs and stricter efficiency targets.
Time-based testing is the most common approach, followed closely by channel holdouts. These methods are easier to implement within more constrained environments where volume is lower and experimentation risk is higher.
For finance teams, incrementality tends to be more structured and deliberate. Tests are often designed to minimize risk while still providing directional clarity, rather than enabling rapid iteration.
Streaming / Entertainment
Streaming and entertainment apps also show a split between 20% to 30% and 30% to 40% lift as a benchmark for success. This shows the importance of both acquisition and longer-term retention in evaluating performance.
Time-based tests are the most common, with platform lift studies and channel holdouts also widely used. This mix suggests that teams are balancing ease of execution with the need for more robust validation.
Because these businesses rely heavily on retention and lifetime value, incrementality is often interpreted over longer time horizons, which makes simpler, short-term tests less definitive on their own.
Shopping / E-commerce
Shopping apps most commonly define good incrementality as 20% to 30% lift, reflecting a balance between growth and efficiency in a competitive acquisition environment.
Time-based tests are the dominant method, followed closely by channel holdouts. These approaches are relatively easy to implement and align well with the fast-paced, campaign-driven nature of e-commerce marketing.
For these teams, incrementality is often used to validate ongoing spend and optimize channel mix, rather than to run highly complex or resource-intensive experiments.
Utility / Productivity
Utility and productivity apps tend to have the lowest threshold for success, with most teams considering 10% to 20% lift meaningful. They focus more on efficiency and consistency over large swings in performance.
Time-based testing is the most common method, followed by budget reduction or pause tests. These approaches allow teams to evaluate performance without requiring large-scale or complex experimentation.
This suggests that for utility apps, incrementality is often used as a practical tool for maintaining efficiency, rather than pushing aggressive growth targets.
Social
Social apps show the widest range in expectations, with teams split between lower (0-20%) and higher (30-40%) lift thresholds. This variability tells the story of differences in monetization models and user behavior across platforms.
Methodologically, social teams use a broad mix of approaches, including channel holdouts, time-based tests, platform lift studies, and MMM or modeled approaches. No single method dominates.
This diversity suggests that social apps operate in more complex or fragmented environments, where teams need to combine multiple approaches to build a complete picture of incremental impact.
Why Teams Don’t Go Further
Most teams believe in the value of incrementality testing. The challenge is not whether it matters, but how easy it is to apply consistently in practice.
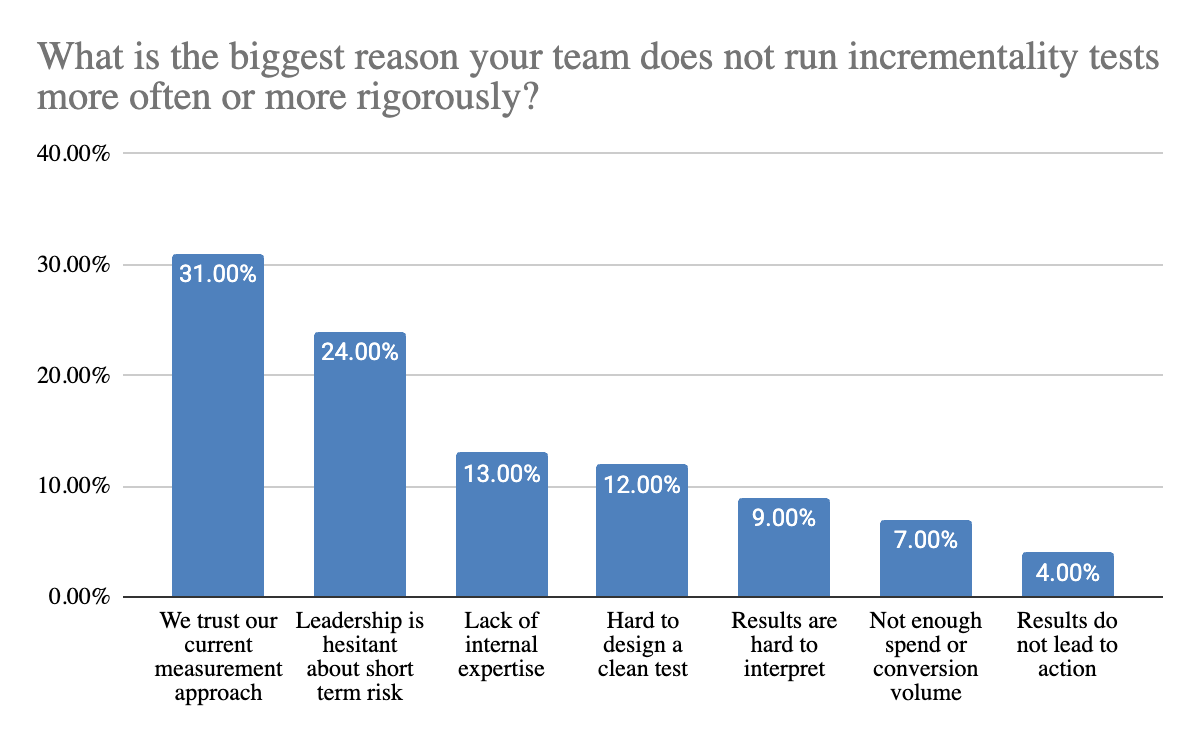
The biggest barrier is not technical, it is confidence in existing measurement. 31% of teams say they do not run incrementality tests more often because they already trust their current approach. This suggests that for many teams, incrementality is not competing with attribution, it is competing with the perceived need to go deeper.
Beyond that, organizational and operational friction play a significant role. 24% of teams point to leadership hesitation around short term risk, such as holding out spend to run a clean test. At the same time, 13% cite a lack of internal expertise and 12% say tests are difficult to design. These challenges make it harder for teams to build a data driven setup where incrementality testing consistently informs decision making..
Interestingly, structural limitations like volume are less of a blocker than expected. Only 7% of teams say they lack the spend or conversion volume needed to run tests. This reinforces that the primary constraints are not always statistical, but a combination of knowledge, process, and internal alignment.
Taken together, these findings point to a broader pattern. The barrier to incrementality is rarely a lack of belief in its value. More often, it is the accumulation of small frictions, across tools, teams, and decision making, that prevent it from becoming a consistent part of how budgets are managed.
From Measurement to Operating Discipline
Incrementality is often treated as a measurement topic. In practice, measurement is central to how growth teams make decisions, but the teams getting the most value from incrementality use it to strengthen and validate those decisions with a clearer understanding of causal impact.
The real shift is operational. High performing teams build a data driven approach to incrementality testing. They define what they want to learn, design tests with that outcome in mind, and use the results to guide budget allocation. Less mature approaches tend to rely on ad hoc testing, where insights are harder to compare and less likely to translate into action.
This is the real benchmark. All teams understand incrementality, but the advantage comes from applying it consistently. The strongest teams integrate incrementality into their decision making process, using it to validate key investments rather than treating it as a one off validation exercise.
Taking ownership of your incremental growth means you need an execution partner who thrives under the microscope. If your team is ready to deploy budget where it drives definitive, net-new growth, discover how Bidease’s AI-powered DSP turns your causal data and predictive targeting into your ultimate competitive advantage. Contact us today.
Customer retention is the key
Lorem ipsum dolor sit amet, consectetur adipiscing elit lobortis arcu enim urna adipiscing praesent velit viverra sit semper lorem eu cursus vel hendrerit elementum morbi curabitur etiam nibh justo, lorem aliquet donec sed sit mi dignissim at ante massa mattis.
- Neque sodales ut etiam sit amet nisl purus non tellus orci ac auctor
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potent
- Mauris commodo quis imperdiet massa tincidunt nunc pulvinar
- Excepteur sint occaecat cupidatat non proident sunt in culpa qui officia
What are the most relevant factors to consider?
Vitae congue eu consequat ac felis placerat vestibulum lectus mauris ultrices cursus sit amet dictum sit amet justo donec enim diam porttitor lacus luctus accumsan tortor posuere praesent tristique magna sit amet purus gravida quis blandit turpis.

Don’t overspend on growth marketing without good retention rates
At risus viverra adipiscing at in tellus integer feugiat nisl pretium fusce id velit ut tortor sagittis orci a scelerisque purus semper eget at lectus urna duis convallis porta nibh venenatis cras sed felis eget neque laoreet suspendisse interdum consectetur libero id faucibus nisl donec pretium vulputate sapien nec sagittis aliquam nunc lobortis mattis aliquam faucibus purus in.
- Neque sodales ut etiam sit amet nisl purus non tellus orci ac auctor
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti
- Mauris commodo quis imperdiet massa tincidunt nunc pulvinar
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti
What’s the ideal customer retention rate?
Nisi quis eleifend quam adipiscing vitae aliquet bibendum enim facilisis gravida neque euismod in pellentesque massa placerat volutpat lacus laoreet non curabitur gravida odio aenean sed adipiscing diam donec adipiscing tristique risus amet est placerat in egestas erat.
“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua enim ad minim veniam.”
Next steps to increase your customer retention
Eget lorem dolor sed viverra ipsum nunc aliquet bibendum felis donec et odio pellentesque diam volutpat commodo sed egestas aliquam sem fringilla ut morbi tincidunt augue interdum velit euismod eu tincidunt tortor aliquam nulla facilisi aenean sed adipiscing diam donec adipiscing ut lectus arcu bibendum at varius vel pharetra nibh venenatis cras sed felis eget.



Let's Talk
We're Here to Help
Start your free consultation today. Create a custom growth strategy with a Bidease specialist.